Portfolio de proyectos
Proyecto: Entrenar un clasificador para detectar emociones en valoraciones de peliculas.
La idea, es resolver el problema de crear un validador de emociones negativas o positivas a la hora de valorar una pelicula de forma textual, mediante el uso de los clasificadores binarios en Machine Learning.
Este ejemplo, podría ser usado para filtrar criticas positivas y criticas negativas a la hora de hacer valoraciones sobre peliculas.
Para entrenar el modelo usaremos un Dataset etiquetado de valoraciones de cine de IMDB.
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
filmsdb = pd.read_csv("IMDBDataset.csv")
filmsdb.head()
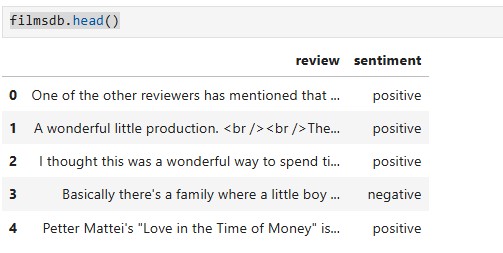
Como vemos, de entrada, la caracteristica review contiene código HTML, esto no nos va a dar ninguna información y nos va a perjudicar la vectorización del texto, por ello, lo que harémos será limpiar esta caracteristica:
#Limpiamos la columna "rewiev" quitando todas las etiquetas HTML que contenga, así como caracteres raros, y espacios innecesarios.
import re
from html import unescape
def limpiar_html(texto):
if isinstance(texto, str):
texto = unescape(texto) # Convierte entidades HTML ( , ", etc.)
texto = re.sub(r'<.*?>', ' ', texto) # Expresión regular que elimina etiquetas HTML como saltos de linea, enlaces, etc.
texto = re.sub(r'\s+', ' ', texto) # Expresión regular que elimina espacios múltiples
return texto.strip() # Quita espacios al inicio y al final del texto.
return texto # Devuelve tal cual si no es texto
# Aplica la limpieza a la columna
filmsdb['review'] = filmsdb['review'].apply(limpiar_html)
Volvemos a visualizar los datos y vemos que las etiquetas HTML han desaparecido.
filmsdb.head()

A continuación, hacemos que pandas nos muestre más información sobre el dataframe, como los Nulos en las caracteristicas, o el tipo de datos de las mismas.
filmsdb.info()
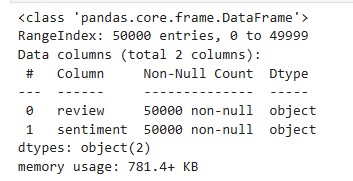
Como vemos que no hay Nulos, no tendremos que ejecutar transformaciones de imputación sobre el cojunto de entrenamiento. A continuación separamos las etiquetas (Y) de las caracteristicas que forman el input (X):
X = filmsdb.drop(columns=['sentiment'])
Y = filmsdb['sentiment']
# Transformarmos a categorica las etiquetas
from sklearn.preprocessing import LabelEncoder
label_encoder = LabelEncoder()
films_prepared_y = label_encoder.fit_transform(Y)
films_prepared_y.shape # Visualizamos las dimensiones del target categorizado
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, films_prepared_y, test_size=0.2)
from sklearn.pipeline import make_pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import SGDClassifier
pipeline = make_pipeline(TfidfVectorizer(max_features=5000, stop_words='english'), SGDClassifier(random_state=42))
pipeline.fit(X_train.squeeze(), y_train)
from sklearn.model_selection import cross_val_predict
# Aquí usamos el pipeline directamente
y_train_pred = cross_val_predict(pipeline, X_train.squeeze(), y_train, cv=3)
Obtenemos la matriz de confusión:
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_train, y_train_pred)
cm

Como vemos obtenemos un resultado bastante bueno, al ser la diagonal principal de la matriz bastante alta en relación a su diagonal secundaria. Aquí tenemos en cuenta la tasa de Verdaderos positivos y verdaderos negativos (diagonal principal) en relación a los Falsos positivos y falsos negativos (diagonal secundaria).
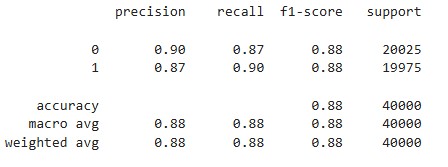
Obtenemos las metricas para las predicciones de la validación cruzada en el conjunto de entrenamiento:
from sklearn.metrics import classification_report
print(classification_report(y_train, y_train_pred))
 A continuación, realizamos la validación cruzada para obtener la función de decision, y con ella calcular la curva de compensación entre precisión y sensibilidad con la libreria matplolib, para ver si podemos ajustar el umbral de alguna manera.
A continuación, realizamos la validación cruzada para obtener la función de decision, y con ella calcular la curva de compensación entre precisión y sensibilidad con la libreria matplolib, para ver si podemos ajustar el umbral de alguna manera.
y_scores = cross_val_predict(sgd_clf, X_train, y_train, cv=3,
method="decision_function")
from sklearn.metrics import precision_recall_curve
precisions, recalls, thresholds = precision_recall_curve(y_train, y_scores)
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 5))
plt.plot(thresholds, precisions[:-1], label='Precisión')
plt.plot(thresholds, recalls[:-1], label='Recall (Sensibilidad)')
plt.xlabel('Umbral de decisión')
plt.ylabel('Valor')
plt.title('Precisión vs. Recall según el umbral')
plt.legend()
plt.grid(True)
plt.show()
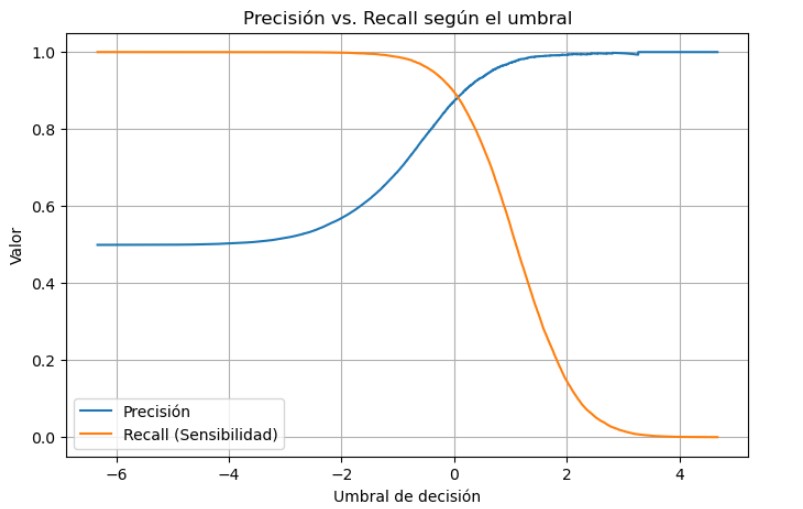
Como vemos, ya esta bastante ajustada la curva de compensación así que, una vez obtenido buenos resultados en el conjunto de entrenamiento, pasamos a testear el modelo con el conjunto de test, obteniendo las métricas bajo este conjunto. Realizamos predicciones con el conjunto de test para poder usar las metricas y medir el resultado.
final_predictions = pipeline.predict(X_test.squeeze())
from sklearn.metrics import classification_report
print(classification_report(final_predictions, y_test))
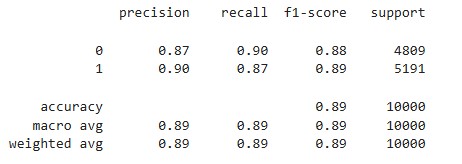
Vemos que se obtienen buenos resultados para el conjunto de test, así que nuestro modelo esta generalizando correctamente. Una vez hecho esto, ya podemos pasarlo a producción, teniendo un modelo funcional.
Podemos comprobar el funcionamiento del modelo con el siguiente formulario:
