Portfolio de proyectos
Proyecto: Pasar de fichero de texto plano secuencial a DataFrame en Pandas (Python)
Durante mi trabajo en entornos de desarrollo en Mainframe me he topado con los ficheros secuenciales, ficheros cuya definición son líneas de datos donde cada campo viene definido por una longitud física en dicho fichero y una lógica por la copy en COBOL que lo aplantilla.
Por consiguiente, estos ficheros de texto plano almacenan una gran cantidad de datos, pero sin una separación entre dichos datos carecen de posibilidad para un tratamiento más profundo de los mismos por otros sistemas.
Por ello he creado esta función en Python que permite convertir un fichero secuencial en un DataFrame de pandas para su posterior análisis mediante técnicas de Machile Learning como una de las posibilidades que podemos obtener.
def crear_dataset(d_head,d_data,list_long):
# d_head es un descriptor de fichero al fichero que contiene la cabecera (un csv por comas simple)
# d_data es un descriptor de fichero al fichero que contiene los datos
# list_long es un vector con las longitudes de cada uno de los campos del fichero
rt_dic = {}
cols_h = d_head.readline().strip().split(",")
#Metemos linea a linea (cada salto de linea) del fichero en una posición del array.
dataje = []
for line_ in d_data:
dataje.append(line_.rstrip())
#Creamos un array por cada clave de cabecera en el diccionario que hemos definido anteriormente
for key_h in cols_h:
rt_dic[key_h] = []
pos=0
index=0
# Rellenamos cada uno de los arrays del diccionario según corresponda
for key_h in cols_h:
for lineadata in dataje:
rt_dic[key_h].append(lineadata[pos:pos+list_long[index]])
pos = pos+list_long[index]
index +=1
# Retornamos el diccionario
return rt_dic
El fichero secuencial con los datos tendrá la forma de:
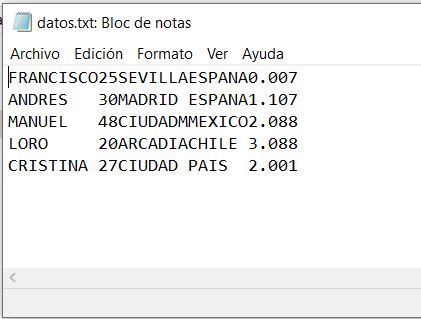
El fichero de cabecera contendrá los nombres de los campos del fichero secuencial:
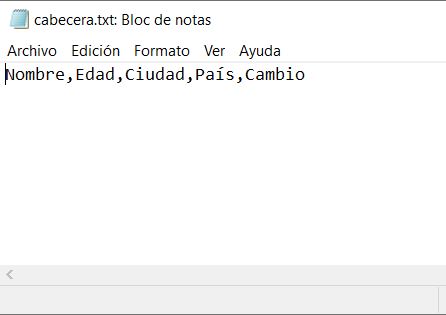
Llamamos de la siguiente forma a la función que transformara el fichero secuencial a Dataframe de pandas:
Con la función open() abriremos en modo lectura "r" los ficheros de cabecera y de datos, almacenando sus descriptores de ficheros en d_head_1 y d_data_2.
En la lista "longits" guardaremos el tamaño de los campos del fichero secuencial, cuanto ocupara el Nombre, la Ciudad, etc...
Guardaremos en la variable de diccionario "dici" el diccionario retornado por la función. Donde pasaremos los tres parametros índicados en los comentarios.
mainpath_d = 'datasets/'
d_head_1 = open(mainpath_d+"customer-churn-model/pruebas/cabecera.txt","r")
d_data_2 = open(mainpath_d+"customer-churn-model/pruebas/datos.txt","r")
longits = [9,2,7,6,5]
dici = crear_dataset(d_head_1,d_data_2,longits)
Importamos pandas en Python y llamamos al metodo DataFrame de pandas.
Por último imprimiremos las primeras columnas con el metodo head() asociado al objeto del DataFrame, para ver que los datos son correctos.
import pandas as pd
da = pd.DataFrame(dici)
da.head()
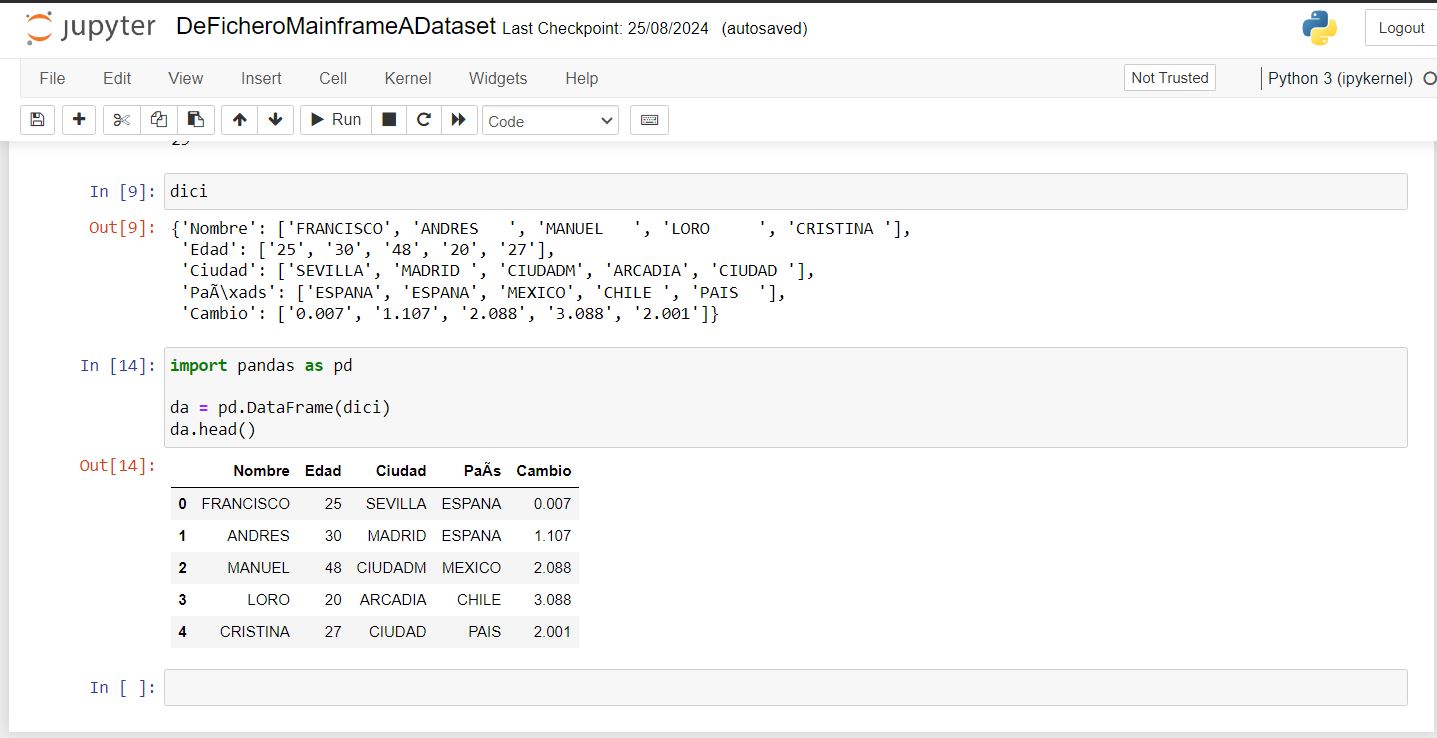
El resultante será el DataFrame obtenido en el Out[14] de Jupyter Notebook.
